Five Things That Actually Change How You Use AI
I used to use AI like a vending machine. Push a button, grab the same generic output everyone else gets, and move on.
That's why most AEC firms getting "AI results" are getting mediocre ones.
After months of using AI daily to run an engineering firm, here's what actually moves the output from generic to useful.
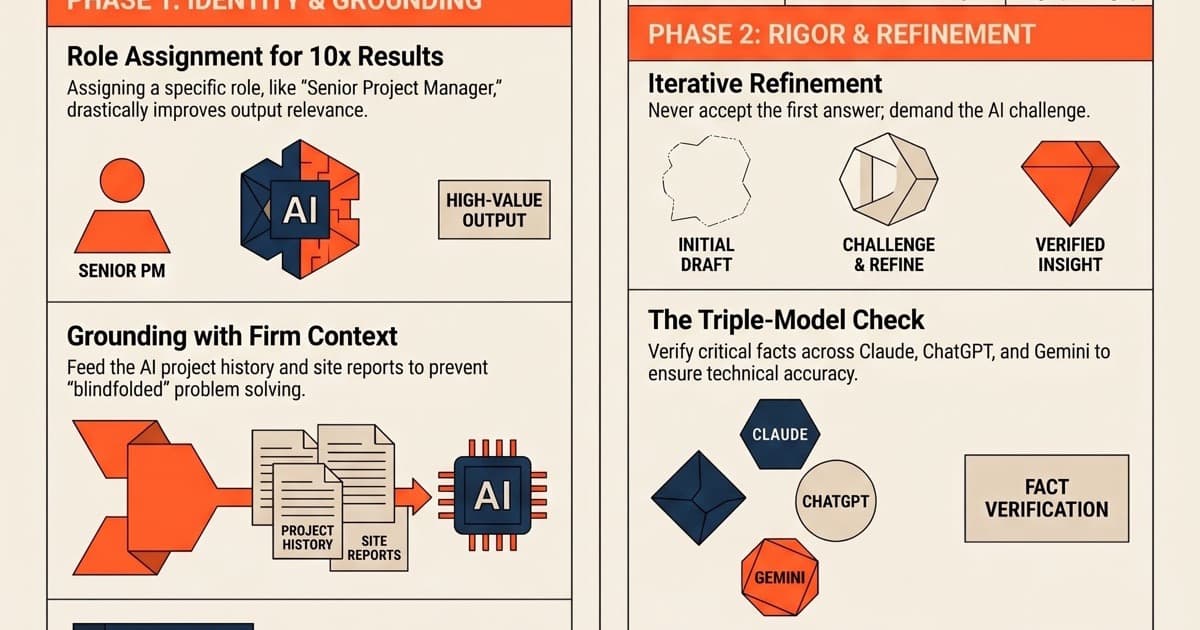
1. Give it a role before you ask anything
"Act as a senior project manager reviewing this RFP" produces wildly different output than a blank prompt. This alone is a 5-10x improvement, and it costs you ten seconds of typing.
The reason: without a role, the model defaults to the average of its training data. With a role, it scopes the response to that persona's vocabulary, priorities, and judgment patterns. A "senior PM" output flags scope risk and schedule float. A blank prompt gives you a Wikipedia summary.
2. Context is everything
The smartest AI sounds clueless without grounding. Feed it your project history, site reports, past schedules. Without that, you're asking a genius to solve a problem blindfolded.
For engineering work specifically: paste in the contract, the spec section, the meeting minutes, the previous RFI. Models trained on the open internet have read zero of your firm's history. Every minute spent giving them context is repaid in output quality.
3. Stop accepting the first answer
Prompting isn't typing. It's iterating. Ask it to think step by step. Ask it to challenge its own answer. The third version is always better than the first.
The first response is the model's safe-bet answer. The second is what happens when you push back. The third is what happens when you push back twice and ask it to assume you're an expert who will catch errors. That third version is the one you can actually use.
4. Cross-verify everything
AI models confidently invent facts. Run the same question through Claude, ChatGPT, and Gemini. If all three agree, you're probably solid. If they diverge, dig deeper.
This matters most on numerical or regulatory questions. "What's the typical liability cap in a FIDIC Yellow Book contract?" should produce three similar answers. If two say 10% and one says 30%, the model is hallucinating, and you need to check the actual text.
5. Demand specificity in every output
No buzzwords. No "consider the following." Real numbers, real examples, clear logic. If your client report reads like a robot wrote it, you haven't pushed hard enough.
A useful test: read the output out loud. If you'd be embarrassed to email it to a client without editing every paragraph, the prompt was lazy. Send it back with "rewrite this with specific examples from the source documents."
The compounding part
None of these techniques are hard. None of them require a different model or a paid subscription. They require treating AI as a collaborator that needs guidance, not a search engine that returns answers.
The gap between firms that understand this and firms that don't is getting wider every month. The ones that figure it out are using the same models as everyone else, just with five extra minutes of setup per task. The ones that don't are concluding "AI is overhyped" because they tried it once and got mediocre output.
Which of these are you already doing, and which one is going to change your next prompt?
Want to see where your firm stands? Take the free AI Readiness Audit — 7 questions, your own 2-page playbook, no sales call.